
Neural video compression dataset and benchmark
Neural Video Compression Dataset
Video traffic constitutes a significant share of global web traffic. To reduce its volume, video codecs have been developed and continuously improved. While the industry has achieved substantial progress in traditional video coding, neural video codecs (NVCs) have recently emerged as a new approach that applies deep learning to video compression. This creates new challenges for compression quality assessment, which is essential for the further development and improvement of such codecs. In particular, it is important to evaluate the novel temporal compression paradigms introduced by NVCs. In this work, we present a large-scale subjective dataset of videos compressed with both neural and traditional video codecs. The dataset includes 2,880 distorted videos with corresponding subjective quality scores. These scores were collected through crowdsourced pairwise comparisons. The proposed dataset provides a valuable resource for the development and benchmarking of video quality metrics tailored to neural video codecs.
Benchmark
Leaderboard
The chart below shows the correlation of metrics with subjective scores on our dataset. You can choose the type of correlation. We recommend that you focus on Spearman’s rank correlation coefficient.
Speed-Quality
Chart below shows Speed-Quality characteristics of metrics.
Data description
The archive contains a set of numbered folders, each corresponding to a specific video.
Inside each folder, you will find several distorted versions of the video along with the original file, named orig.mkv.
The file Subjective_scores.csv provides subjective quality scores for each method on each video, along with a brief description of the applied distortions.
Methodology
Video preparation
To assemble a representative set of high-quality source videos, we first defined requirements on visual fidelity, diversity of content, and licensing constraints. Candidate material was gathered from publicly available platforms, including Vimeo, Xiph.Org and YouTube UGC, resulting in a large initial pool. To ensure that the source content was not affected by strong pre-existing compression artifacts, only videos with bitrates above 20 Mbps were retained. All selected videos were converted to a unified YUV 4:2:0 format to standardize further processing. Only videos available under permissive licenses (CC BY or CC0) were considered.
We computed spatial and temporal complexity characteristics for all videos in the dataset. Spatial complexity was estimated as the average size of x264-encoded I-frames normalized by the uncompressed frame size, while temporal complexity was defined as the ratio between the average sizes of P-frames and I-frames.
Rather than directly selecting videos from this pool, we aimed to ensure broad and balanced coverage of content characteristics. For this purpose, each candidate video was described using spatial and temporal complexity indicators, capturing variations in motion and structural detail. These descriptors were then used to organize the dataset via K-means clustering into 80 groups, each representing a distinct region of the content space. From every group, a small subset of videos was sampled and manually inspected, after which a single representative example was chosen. This selection process was guided by the goal of achieving both visual quality and diversity across semantic categories.
As a result, the final reference set covers a wide range of scenarios, including dynamic scenes such as sports and gaming, natural environments, talking-head and interview footage, broadcast and animation content, as well as various forms of user-generated material (e.g., vlogs and advertisements). Particular attention was also given to include visually specific patterns such as water surfaces and close-up facial content, which are known to be challenging for compression and quality assessment. Also we have included several screen content videos from the ~\cite{safonov2025screen} collection.
For the distorted video generation, we selected six modern neural video codecs: OpenDVC, DCVC-RT, NEVC, GLC, BRHVC, and DHVC. These codecs represent different approaches to neural compression and produce a variety of artifacts. For each codec, we generated compressed sequences at four rate–distortion settings to cover a wide range of quality levels. This setup allows us to capture diverse compression artifacts, including those specific to neural methods, and enables comparison with traditional codecs under similar conditions. We included four standard codecs corresponding to widely used compression standards H.264/AVC, H.265/HEVC, H.266/VVC, and AV1 to provide a consistent baseline for comparison. The details on codecs presets and settings may be found in the supplementary.
Subjective Test
We employed a subjective pairwise comparison protocol to rank the distorted video sequences. Annotations were collected via crowdsourcing using a sequential preference interface. In each trial, participants were presented with two videos one-by-one and asked to indicate which one had higher visual quality. Three response options were provided: \textit{left}, \textit{right}, or \textit{cannot decide}. Each participant evaluated 12 video pairs, including 2 hidden validation pairs with known ground truth.
The validation pairs were constructed by compressing reference videos using high CRF values, producing clearly distinguishable quality differences. These pairs were randomly interleaved with the test samples, and participants were not informed about their presence or purpose. Only responses from participants who correctly answered both validation pairs were retained. To ensure statistical consistency, the comparison graph was balanced such that each video pair received exactly 10 valid annotations. In total, the dataset includes responses from more than 12{,}000 unique participants.
IQA methods calculation
Due to the results of our small (in terms of the data size) research for IQA methods Mean Temporal Pooling was selected as a way of aggregatig of each frame scores.
Therefore, to get a quality score for a video using IQA methods, we compared the given distorted sequence frame by frame with the corresponding frames of the reference video and then averaged calculated scores. The research mentioned above will be reproduced with more data in the future.
- To encode the video we used the following command:
ffmpeg −f rawvideo −vcodec rawvideo −s {width}x{height} −r {FPS} −pix_fmt yuv420p −i {video name}.yuv −c:v libx265 −x265−params " lossless =1:qp=0" −t {hours : minutes : seconds} −vsync 0 {video name}.mp4
- To decode the video back to YUV you can use:
ffmpeg -i {video name}.mp4 -pix_fmt yuv420p -vcodec rawvideo -f rawvideo {video name}.yuv
- To convert the encoded video to the set of PNG images you can use:
ffmpeg -i {video name}.mp4 {frames dir}/frame_%05d.png
Correlation coefficients
To calculate correlation measure subjective scores and metric’s output we chose Spearman’s Rank Correlation Coefficient (SRCC), Kendall’s Rank Correlation Coefficient (KRCC). Both measure the prediction monotonicity (the limit, to which the quality scores of a metric agree with the relative magnitude of the subjective scores).
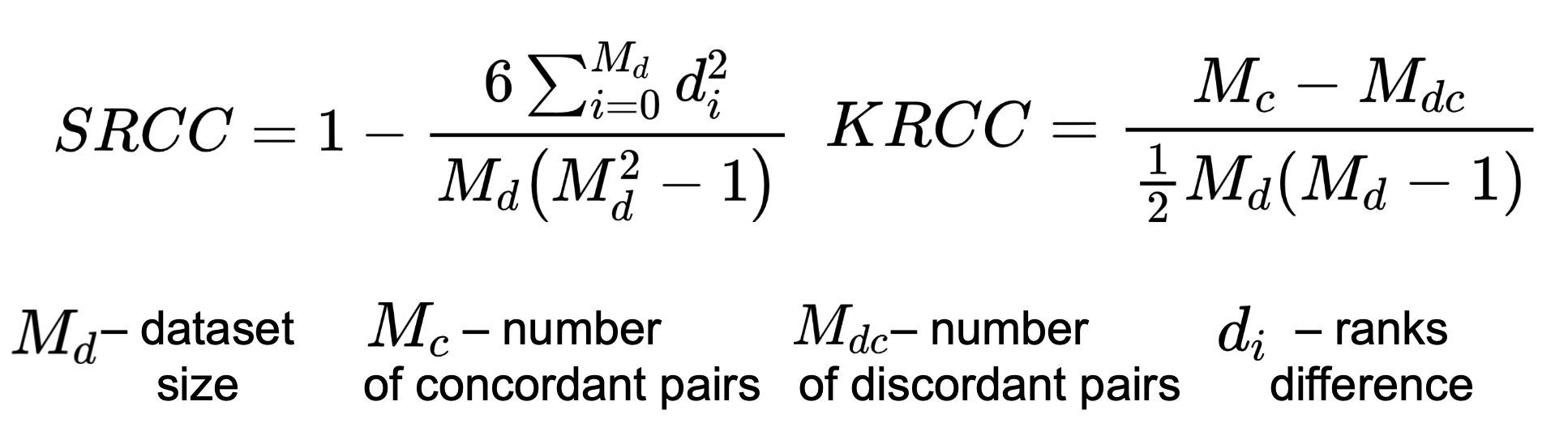
Speed perfomance
We have also measured the metrics speed performance, expressed in FPS (the execution time of a full model runtime divided by the number of sequence frames).
- Used videos:
- 5 reference videos
- 3 metric calculation for each distorted video
- 15 compressed videos and 45 total amount of measurements
- Output: maximum FPS of metric on any video.
- Calculations were made using the following hardware:
- NVIDIA Titan RTX GPU
- 64 CPUs cluster, Intel(R) Xeon(R) Silver 4216 CPU @ 2.10GHz
Metrics
| Name | IQA/VQA | Type | Implementation |
|---|---|---|---|
| ARNIQA [3] | IQA | NR | Link |
| BRISQUE [5] | IQA | NR | Link |
| CLIP IQA [7] | IQA | NR | Link |
| CLIP-IQA+ [8] | IQA | NR | Link |
| CONTRIQUE [12] | IQA | NR | Link |
| COVER [13] | VQA | NR | Link |
| CVRKD [14] | IQA | FR | Link |
| DBCNN [15] | IQA | NR | Link |
| DISTS [16] | IQA | FR | Link |
| DOVER [17] | VQA | NR | Link |
| EONSS [21] | IQA | NR | Link |
| FSIM [25] | IQA | FR | Link |
| FasterVQA [26] | VQA | NR | Link |
| HyperIQA [32] | IQA | NR | Link |
| IW-SSIM [33] | IQA | FR | Link |
| KonCept512 [34] | IQA | NR | Link |
| Koncept [35] | IQA | NR | Link |
| LINEARITY [36] | IQA | NR | Link |
| LIQE [37] | IQA | NR | Link |
| LPIPS [38] | IQA | FR | Link |
| MANIQA [43] | IQA | NR | Link |
| MDTVSFA [45] | VQA | NR | Link |
| MEON [46] | IQA | NR | – |
| MUSIQ [52] | IQA | NR | Link |
| PAQ-2-PIQ [56] | IQA | NR | Link |
| PIQE [57] | IQA | NR | Link |
| PSNR | IQA | FR | MSU VQMT |
| RankIQA [60] | IQA | NR | Link |
| SPAQ [61] | IQA | NR | Link |
| SSIM [63] | IQA | FR | MSU VQMT |
| TOPIQ [70] | IQA | FR | Link |
| TRES [71] | IQA | NR | Link |
| VMAF [75] | VQA | FR | MSU VQMT |
| VQM | VQA | FR | MSU VQMT |
Contact us
For questions, propositions please contact authors: nikolay.safonov@graphics.cs.msu.ru, nikita.gornostaev@graphics.cs.msu.ru, alexandra.dubonos@graphics.cs.msu.ru, dmitriy@graphics.cs.msu.ru